Improved error reporting #129
Conversation
for context and line numbers.
moo.js
Outdated
| var eol = token.lineBreaks ? token.text.indexOf('\n') : token.text.length | ||
| var firstLine = this.buffer.substring(start, token.offset + eol) | ||
|
|
||
| var lines = this.buffer.split("\n") |
There was a problem hiding this comment.
We avoid using split here because we've already tokenized the input. Error handling doesn't necessarily need to be as fast as the happy path, but it could potentially be an issue if the input buffer is large.
There was a problem hiding this comment.
We avoid using
splithere because we've already tokenized the input. Error handling doesn't necessarily need to be as fast as the happy path, but it could potentially be an issue if the input buffer is large.
We could walk the string backwards instead if that is a concern.
There was a problem hiding this comment.
Walking backwards (and forwards—see my comment) is a better option. Tokenizers often deal with very large inputs.
I'm not convinced about this, either; if you want the error token, can't you define one explicitly? |
Could you elaborate? Do you have concerns about effects that the change could cause? Or don't think the issue is important? I'd be happy to work on the code more to make it satisfactory to you, but if you are not interested at all to merge this then I will leave it alone. |
I wanted to display the character that the lexer errored on within the parser error message. This was not possible without reaching in to the non-public api of the lexer (as specified on the Nearley website) to access its current index and buffer. I felt that passing this token back is slightly better than doing that. Open to other suggestions though. |
|
It looks like your terminal emulator is treating the unicode arrow as either fullwidth or proportional width, as many emulators do, so it only sort of lines up with the character it's trying to point to. It's better just to use a caret/circumflex ( I find context lines in error messages quite useful, and line numbers marginally so. However, you've implemented context wrong: you should give n lines on both sides of the problematic one, not just n lines before. It's much more useful to see this: than this: (See, e.g., the Another formatting nit: there should be at least two columns between line numbers and code: two spaces, a full stop and a space, or something similar. @tjvr I don't have a problem with making this the default behavior, but if you'd like to be consistent with previous versions and/or keep error messages less bulky, perhaps we could make it an option to |

{kind=link}
moo.js
Outdated
| return pad(token.line - lines.length + i + 1, lastLineDigits) + " " + line; | ||
| }) | ||
| .join("\n") | ||
| message += "\n" + pad("", lastLineDigits + token.col) + "⬆︎\n" |
There was a problem hiding this comment.
Error messages should not end with blank lines unless you have a Really Good Reason™. I'd get rid of the terminal \n.
moo.js
Outdated
|
|
||
| function pad(n, length) { | ||
| var s = String(n) | ||
| return Array(length - s.length + 1).join(" ") + s |
There was a problem hiding this comment.
Even though you never violate this invariant, it makes me uncomfortable (i.e., will trip up future maintainers) that this function will throw if you give it something longer than length, since functions like pad usually don't. Either inline the code (since you made the function local and you only call it once) or make it more robust and put it with the other utility functions at the top.
moo.js
Outdated
| var eol = token.lineBreaks ? token.text.indexOf('\n') : token.text.length | ||
| var firstLine = this.buffer.substring(start, token.offset + eol) | ||
|
|
||
| var lines = this.buffer.split("\n") |
There was a problem hiding this comment.
Walking backwards (and forwards—see my comment) is a better option. Tokenizers often deal with very large inputs.
|
I agree with all of Nathan's comments. Since he's happy to make this the default, so am I. I think I'd rather have bulkier error messages for everyone than introduce extra arguments to As above, I'd rather not attach the token object to the error message, but it sounds like we have to. |
|
Nice! I appreciate the feedback. I plan to address the mentioned issues soon. Here I'll summarize what I am planning to do:
If either of you would like to change this list please give me a heads up. I plan to start work some time tomorrow. |
Neither. Return the original string, like |
Okay. |
Revert arrow character to ^. Error handling in pad function Revert attaching of invalid token to error.
|
New code is in! Please take a look. |
moo.js
Outdated
| @@ -559,6 +593,8 @@ | |||
| } | |||
| } | |||
|
|
|||
| Lexer.prototype.lastNLines = lastNLines | |||
There was a problem hiding this comment.
I don't think we want to export this.
There was a problem hiding this comment.
That's the only way I could write tests for it. Do you know of another way? Or we could ditch the tests, which I am okay with too.
There was a problem hiding this comment.
Removed this and removed tests.
moo.js
Outdated
| @@ -53,6 +53,39 @@ | |||
| } | |||
| } | |||
|
|
|||
| function pad(n, length) { | |||
| var s = String(n) | |||
There was a problem hiding this comment.
Why are we calling String() here?
There was a problem hiding this comment.
I supposed that superfluous if we simply assume the input is a string. I can get rid of it if you prefer.
|
I would love to see this merged.... if (err.stack.match(/.*moo\.js.*/)) {
const m = err.message.match(/.*line (\d+) col (\d+)/)
const newErr = new CompilerError(err.message)
err.position = {line: parseInt(m[0]), col: parseInt(m[1])}
throw newErr
}This is the sketchy workaround I had to use to differentiate lexer errors and get the position out. :P |
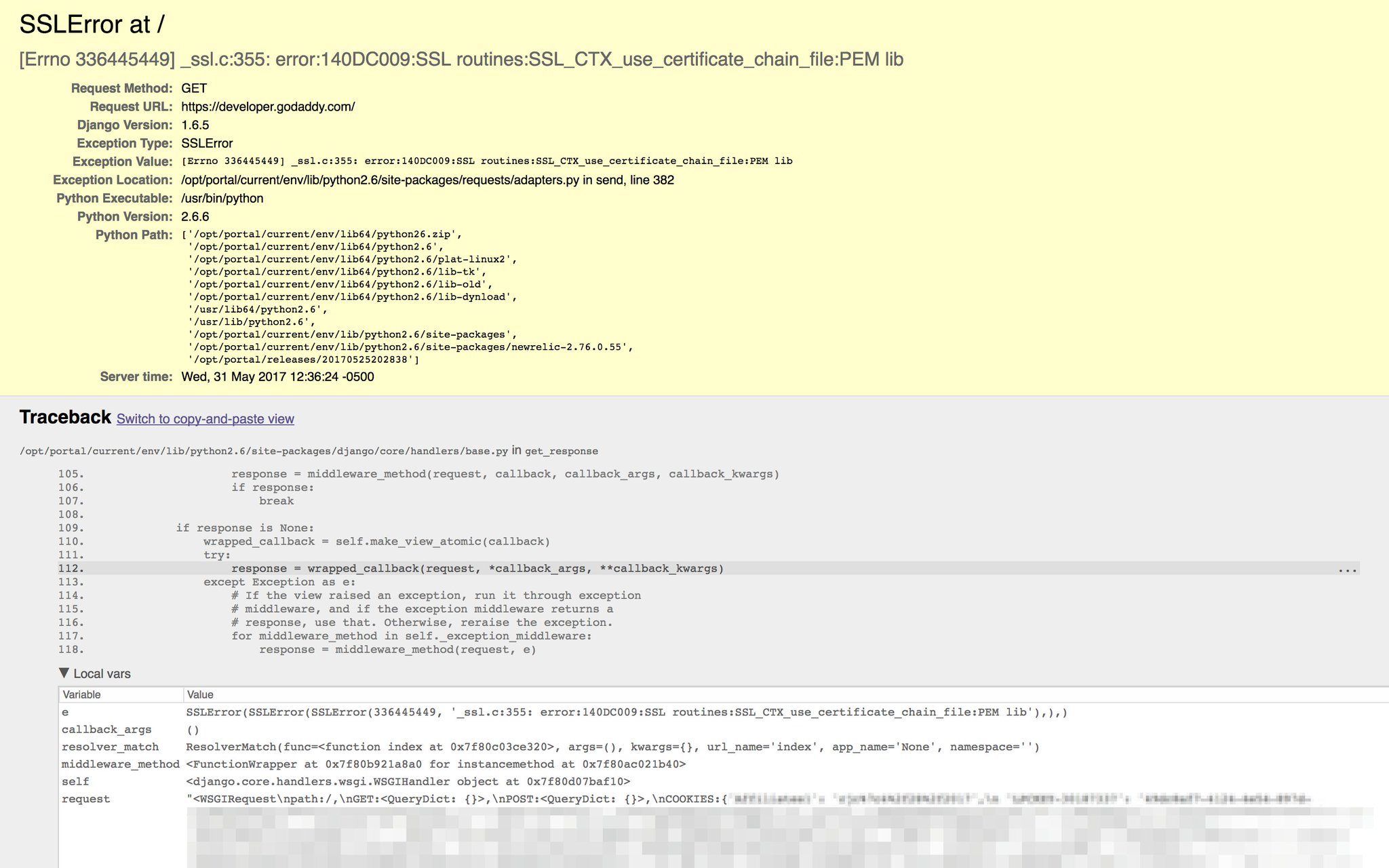
This PR aims to improve the error message displayed to the user when a syntax error is encountered by the lexer. In particular:
This PR is related to kach/nearley#459.
Screenshot: